
When Mozilla announced Pocket was shutting down, I had 4,405 bookmarks in there. Articles I'd saved since 2014. Dev resources, long reads, random rabbit holes from long browsing sessions. Years of "I'll read this later"
The alternatives I tried all felt wrong: cluttered dashboards, core features locked behind paywalls, even worse, apps that just saved the URL without actually fetching the content, so half your archive rots when the original pages go down
I was already building Loreo, a self-hostable read-later app partly as a replacement for Pocket. The CSV import feature wasn't on a roadmap. It was the first real thing I needed it to do
First attempt: Chrome headless, and the links that said nothing
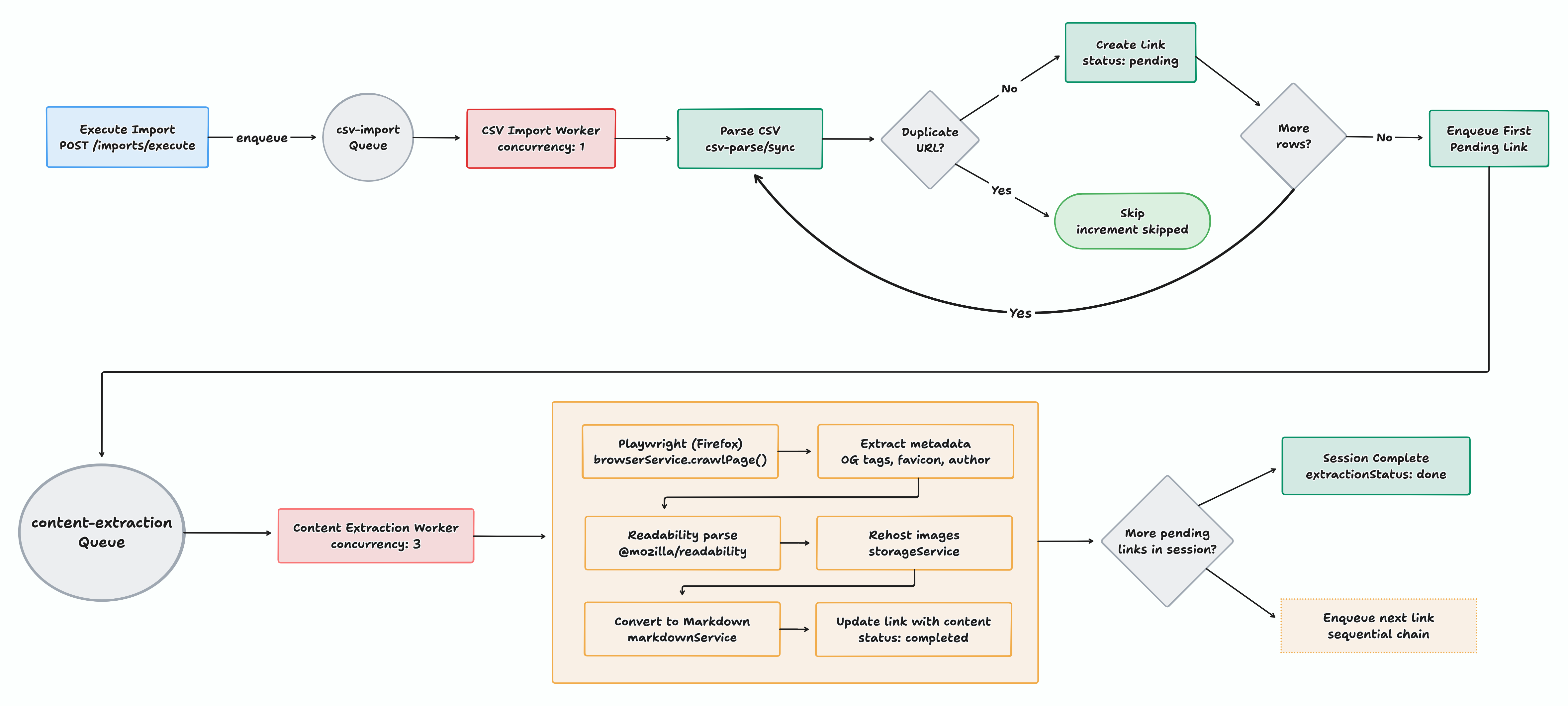
The pipeline was straightforward on paper: upload a CSV, map the columns, spin up a background worker that crawls each URL with a headless browser, extract the readable content via Mozilla's Readability, re-host the images, convert everything to Markdown. Two BullMQ queues chained together: CSV import and content extraction
I started with Chrome headless. Some links crawled fine. Others just... hung. No error, timeout, or log output. The worker would sit there active in the queue while the URL did nothing, the server accepting the TCP connection and then going silent
The frustrating part wasn't the failure. It was that it gave me nothing to work with. Just a console stuck at "Crawling..."
The "good citizen" phase
My first instinct was that anti-bot detection was the culprit. So I tried to look less like a bot
I tried puppeteer-extra-stealth-plugin combined with Ghostery adblocker, and rotating user agents to mimic real browser fingerprints. The idea was to crawl like a good citizen: casually browsing, human-looking, not hammering servers. It helped with some pages. The stubborn ones still hung silently
I spent more time on this than I want to admit. No meaningful logs or pattern I could identify across the problematic URLs. Some were media sites, some were old personal blogs. At some point I made a pragmatic call: skip the links that cause problems, keep the pipeline moving, and come back later. It wasn't a fix, but it unblocked the process
Camoufox
The actual fix came from finding Camoufox, a headless Firefox wrapper built specifically for undetected browser automation. Unlike stealth plugins bolted onto Chrome, it patches Firefox at a deeper level to pass bot detection checks more convincingly. Once I switched to it and ran the worker against the same problematic URLs, they crawled
That became the stack: Camoufox as the browser layer, Playwright for control, Mozilla's Readability for content extraction. I tested it with 100 links, it ran perfectly. Then 200 links, still smooth. The architecture felt solid: two workers, sequential extraction chaining within each import session to keep browser memory sane, batch writes with pauses for PostgreSQL
I kicked off the real import. All 4,405 links. And left it to run overnight
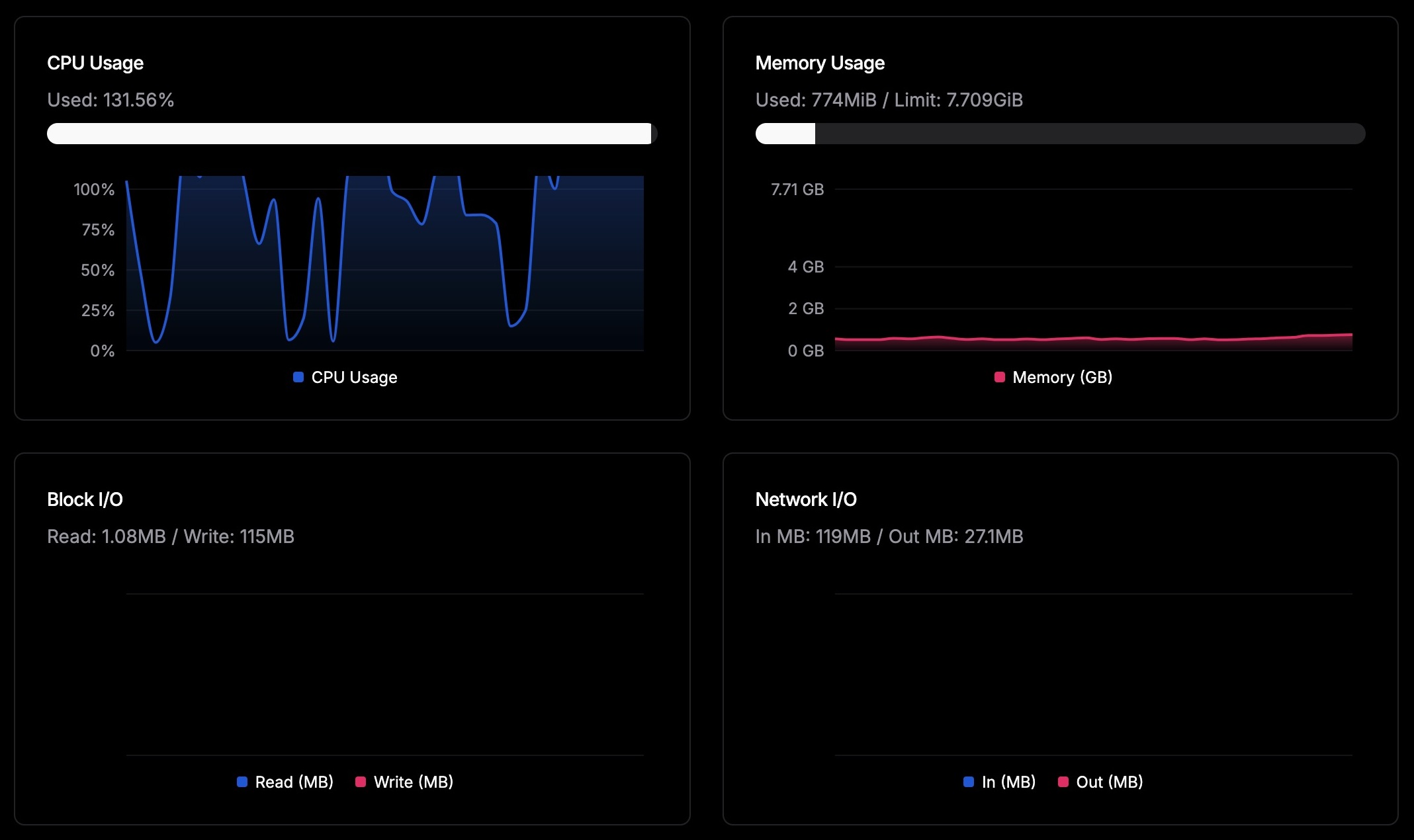
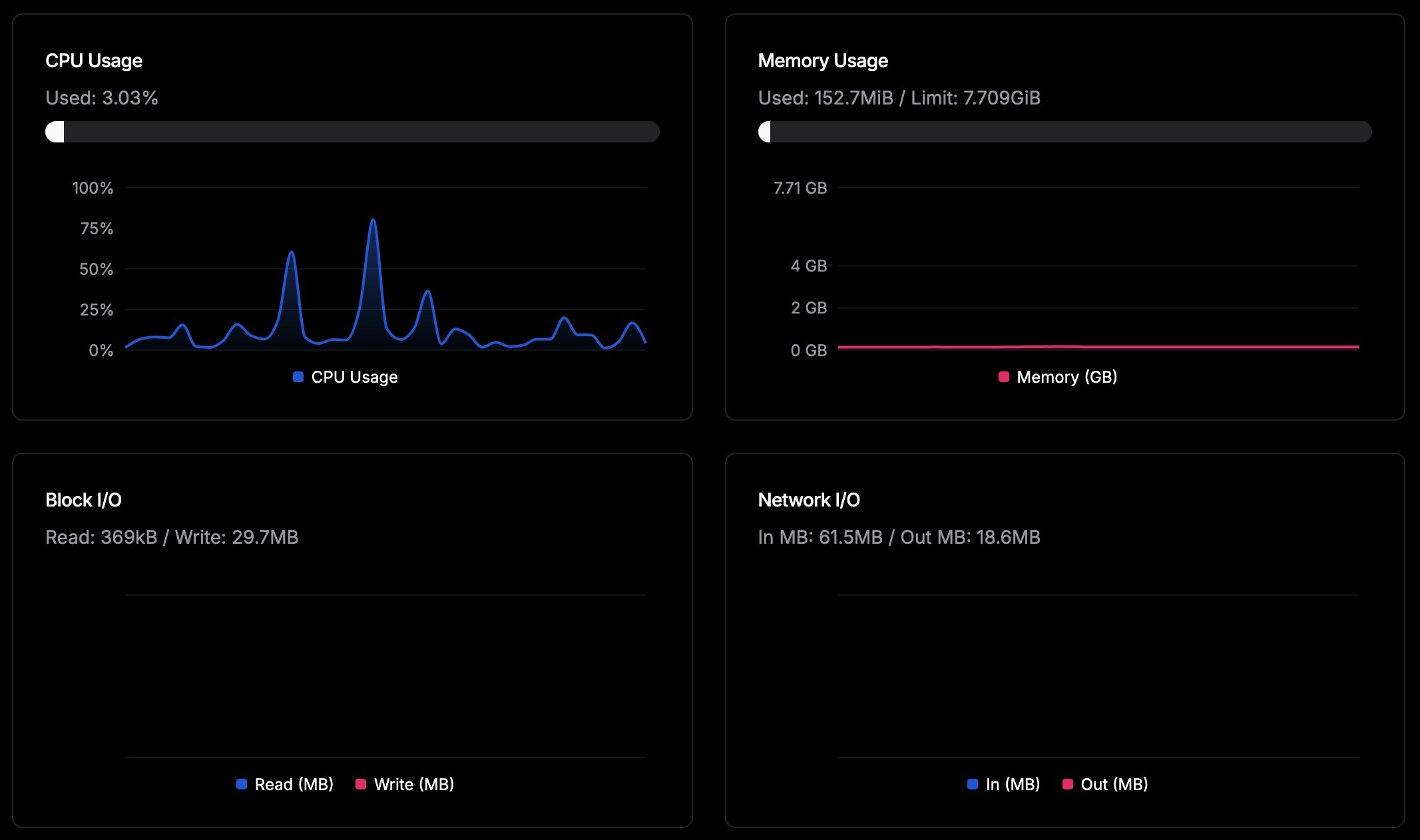
Importing 4,405 Pocket links on a production instance. Most of the workload is concentrated in the browser container while the server remains relatively idle
The fan
Here's what the content extraction worker was supposed to do:
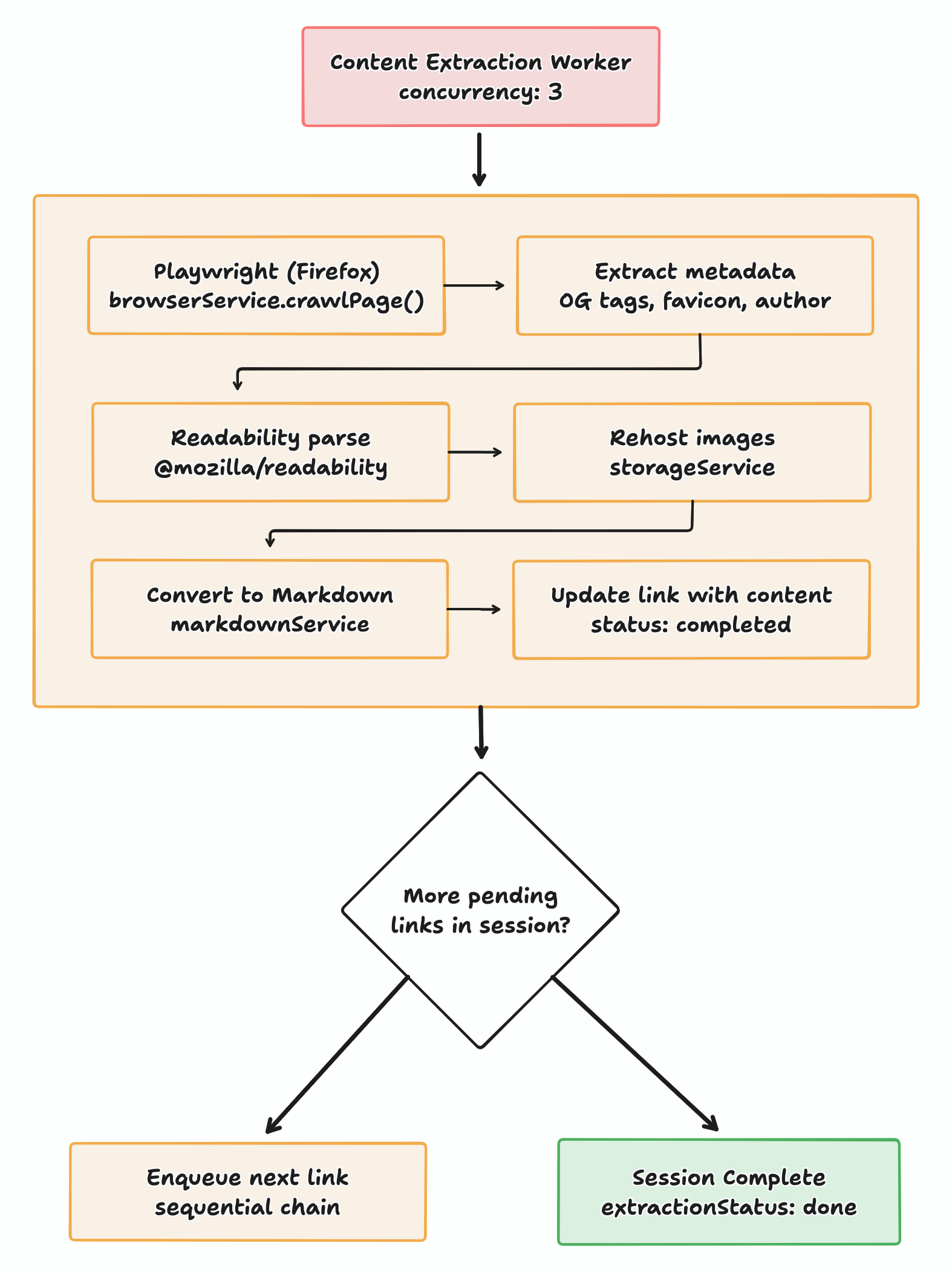
What actually happened was a different story. I came back to my laptop running at full-blast: it sounded like it was preparing for takeoff
OrbStack showed a high memory usage with a dozen Firefox processes running, each consuming 700MB+ of RAM. The BrowserService was supposed to be a singleton; one persistent Firefox instance, shared across extraction jobs via a mutex, each job getting its own isolated browser context. The mutex was there to prevent concurrent browser instance creation function calls
Under load, it didn't hold. Three extraction jobs would simultaneously see the browser as disconnected and each try to create a new Firefox instance. The old processes weren't cleaned up, so memory usage kept climbing
I tried adding a semaphore on top of the mutex, but it still leaked. The root issue was trying to manage a browser's lifecycle from inside a Node.js process: synchronizing two separate event loops through locks and connection checks is just asking for edge cases you can't fully anticipate
The better mental model: treat the browser as an external service, not a managed child. Run it as a standalone process, connect via WebSocket, let the server handle restarts. Your app code should assume the browser is unreliable and handle that gracefully, not try to own its lifecycle
The link that froze everything
With the memory issue partially contained, I restarted. Progress resumed then the logs went quiet again. Dashboard stuck at processing phase with no movement for several minutes
One content extraction job was stuck in active phase. An old personal blog from years ago, still technically online, but the server was accepting connections and never sending a response body. Playwright's navigation timeout only starts counting after navigation begins: if the server accepts the TCP handshake and then does nothing, the timeout never fires. The job just sits there
The worst part: because extraction within a session is sequential by design; to keep browser memory under control, this one frozen link was blocking all 3,200 remaining links from being processed. The queue had concurrency, but this session's chain was locked behind a dead URL
The fix was defense-in-depth timeouts: an abort signal that races against the entire crawl operation, including the connection phase, not just the navigation. And when a link fails, mark it and move on immediately. The user would rather have 3,400 successful extractions and 600 failures than 800 successes and 3,200 stuck in a queue
The library that crashed twice
I restarted again. This time it ran properly; 1,200 links in, then a crash. The metadata extraction library metascraper threw an unhandled exception on a page with malformed tags which brought the worker process down. I restarted it, it crashed again. Same library, different edge case
The metascraper is genuinely well-designed. Rule-based, plugin architecture, handles most pages correctly. But across 4,000 pages that includes blogs, news sites, forums, pages from years ago, pages with no metadata at all, the edge cases started to pile up. Each crash forced BullMQ to restart the worker, losing the in-flight job and breaking the extraction chain
The problem space is actually small: HTML metadata extraction is a cascade of DOM queries; author, date, image, OpenGraph tags, and favicon, each falling back to the next available source. I decided to make an utility about 30 lines of code, every null case falls to the next fallback and nothing throws
I replaced metascraper with that function. The next run processed all 4,000 links without a single crash
The lesson isn't that libraries are bad. It's that for a narrow, well-understood problem, a custom solution hands you the failure modes. You know exactly what can go wrong, because you wrote it
The numbers
| Metric | Value |
|---|---|
| Links imported | 4,405 |
| CSV import duration | ~13 minutes (20 links per second) |
| Content extraction (per link) | 3–30 seconds |
| Successfully extracted | ~94% (4,126) |
| Failed (timeout, paywall, 404) | ~6% (279) |
| Total images rehosted | ~3,440 |
| DB growth after import | ~68MB |
The 6% failure rate is what a real bookmark collection looks like: links rot, sites go paywalled, some pages are pure client-side JavaScript with nothing for Readability to extract, even some have their domain expired. The pipeline marks them as failed to extract with a reason; the user can see which ones didn't make it and decide what to do
What actually took a full day
The architecture was mostly right. The bugs were in the assumptions that a browser singleton would hold under load, that Playwright's timeouts covered all the failure modes, that a well-maintained library would handle 4,000 edge cases without issue. None of those are unreasonable assumptions. They just didn't survive contact with a real dataset
My 4,405 Pocket links are in Loreo now. Most of them with full content, images re-hosted, and searchable. The pipeline has handled larger imports since, and the same three bugs haven't come back
It's not perfect. There are still rough edges I know about. But it works well enough to matter, and I built it for myself first, which means I'll keep fixing it
Loreo is an open-source, self-hostable read-later app. Source on GitHub
Read the case study to learn why I'm building it